
python语法[module/package+import]
一 module
通常模块为一个文件,直接使用import来导入就好了。
可以作为module的文件类型有”.py”、”.pyo”、”.pyc”、”.pyd”、”.so”、”.dll”。
二 package
通常包总是一个目录,可以使用import导入包,
或者from + import来导入包中的部分模块。
包目录下为首的一个文件便是 __init__.py。
然后是一些模块文件和子目录,
假如子目录中也有 __init__.py 那么它就是这个包的子包了。
一、import语句
在开始使用一个模块中的函数之前,必须用import语句导入该模块。
二、from import语句
这是导入模块的另一种形式,使用这种形式的 import 语句, 调用 模块中的函数时不需要 moduleName. 前缀 。但是,使用完整的名称会让代码更可读,所以最好是使用普通形式的 import 语句 。
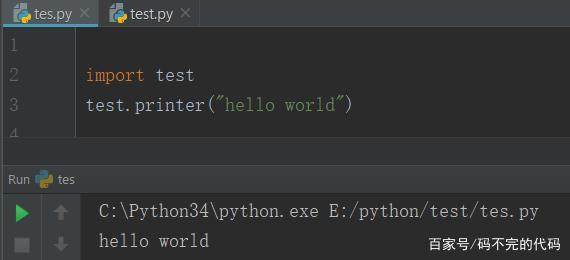
在python中导入模块绝对是我们最最常用的功能,基本每个py文件中都会有import或者是from import语句。可是,这两种导入方法有什么不同,又该怎么用呢?今天就好好来分析一下。
先上他俩的定义:
模块导入允许我们将一个个独立的程序功能分别实现然后组合成一个复杂的系统。
主要有如下作用:
代码重用:我们知道当一段代码需要用到两次的时候,我们就需要写一个函数了这是一个道理。
避免变量名的冲突:每个模块都将变量名封装进了自己包含的软件包,这可以避免变量名的冲突。除非使用精确导入。
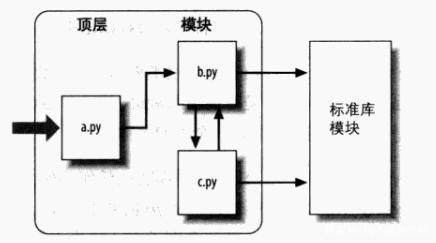
import语句
import语句就像这样
也可以在一行内导入多个模块:
但是这样的代码可读性不如多行的导入语句。 而且在性能上和生成 Python 字节代码时这两种做法没有什么不同。 所以一般情况下, 我们使用第一种格式。
Import工作方式:
其中,导入程序搜索的目录如下:
import解释:
解释器执行到import语句, 如果在搜索路径中找到了指定的模块, 就会加载它。该过程遵循LEGB作用域原则, 如果在一个模块的顶层导入, 那么它的作用域就是全局的; 如果在函数中导入, 那么它的作用域是局部的。 如果模块是被第一次导入, 它将被加载并执行
例子:
Import as语句
有时候你导入的模块或是模块属性名称已经在你的程序中使用了, 或者你不想使用导入的名字。可能是它太长不便输入什么的, 总之你不喜欢它。 这已经成为 Python 程序员的一个普遍需求: 使用自己想要的名字替换模块的原始名称。一个普遍的解决方案是把模块赋值给一个变量:
这样便于自己使用
from-import 语句
你可以在你的模块里导入指定的模块属性。 也就是把指定名称导入到当前作用域。 使用
from-import 语句可以实现我们的目的, 它的语法是:
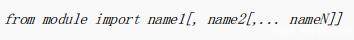
From *
当我们使用from * 的时候,会取得模块顶层左右赋值的变量名的拷贝。
注意:当我们使用这种方法导入的时候,就会出现变量名的重复问题,因为我们把另外一个模块中所有的变量名都导入了进来,在命名的时候会出现命名冲突的情况。
导入只发生一次
个模块只被加载一次, 无论它被导入多少次。 这可以阻止多重导入时代码被多次执行。 例
如你的模块导入了 sys 模块, 而你要导入的其他 5 个模块也导入了它, 那么每次都加载 sys (或是其他模块)不是明智之举! 所以, 加载只在第一次导入时发生。
Import 和from是赋值语句
像def一样,import和from是可执行的语句,他们可以出现在if中,可以出现在函数中,执行到这些语句的时候才会进行解析,也就是说,被导入的模块和变量名只有在对应的import或from语句执行后才可以使用。
Import将整个模块对象赋值给一个变量名。
From将一个或多个变量名赋值给另外一个模块中同名的对象。所以from容易污染命名空间。
为什么不建议用 “from module import *”
在实践中, “from module import *” 不是良好的编程风格,如果使用from导入变量,且那些变量碰巧和作用域中现有变量同名,那么变量名就会被悄悄覆盖掉。使用import语句的时候就不会发生这种问题,因为我们是通过模块名才获取的变量名,像module.attr不会和现有作用域的attr冲突。
何时使用from import:
我们只在两种场合下建议使用这样的方法, 一个场合是:目标模块中的属性非常多, 反复键入模块名很不方便 , 例如 Tkinter (Python/Tk) 和 NumPy (Numeric Python) 模块 , 可能还有 socket 模块。
另一个场合是在交互解释器下, 因为这样可以减少输入次数。
一 module
通常模块为一个文件,直接使用import来导入就好了。可以作为module的文件类型有”.py”、”.pyo”、”.pyc”、”.pyd”、”.so”、”.dll”。
二 package
通常包总是一个目录,可以使用import导入包,或者from + import来导入包中的部分模块。包目录下为首的一个文件便是 __init__.py。然后是一些模块文件和子目录,假如子目录中也有 __init__.py 那么它就是这个包的子包了。
参考:http://wiki.woodpecker.org.cn/moin/PythonEssentialRef8
一 、模块
你可以使用import语句将一个源代码文件作为模块导入.例如:
# file : spam.py
a = 37 # 一个变量
def foo: # 一个函数
print "I'm foo"
class bar: # 一个类
def grok(self):
print "I'm bar.grok"
b = bar() # 创建一个实例
使用import spam 语句就可以将这个文件作为模块导入。系统在导入模块时,要做以下三件事:
1.为源代码文件中定义的对象创建一个名字空间,通过这个名字空间可以访问到模块中定义的函数及变量。
2.在新创建的名字空间里执行源代码文件.
3.创建一个名为源代码文件的对象,该对象引用模块的名字空间,这样就可以通过这个对象访问模块中的函数及变量,如:
import spam # 导入并运行模块 spam print spam.a # 访问模块 spam 的属性 spam.foo() c = spam.bar() ...
用逗号分割模块名称就可以同时导入多个模块:
import socket, os, regex模块导入时可以使用 as 关键字来改变模块的引用对象名字: import os as system
import socket as net, thread as threads
system.chdir("..")
net.gethostname()
使用from语句可以将模块中的对象直接导入到当前的名字空间. from语句不创建一个到模块名字空间的引用对象,而是把被导入模块的一个或多个对象直接放入当前的名字空间:
from socket import gethostname
# 将gethostname放如当前名字空间
print gethostname() # 直接调用
socket.gethostname() # 引发异常NameError: socket
from语句支持逗号分割的对象,也可以使用星号(*)代表模块中除下划线开头的所有对象:
from socket import gethostname, socket from socket import * # 载入所有对象到当前名字空间
不过,如果一个模块如果定义有列表__all__,则from module import * 语句只能导入__all__列表中存在的对象。
# module: foo.py __all__ = [ 'bar', 'spam' ] # 定义使用 `*` 可以导入的对象
另外, as 也可以和 from 联合使用:
from socket import gethostname as hostname h = hostname()
import 语句可以在程序的任何位置使用,你可以在程序中多次导入同一个模块,但模块中的代码*仅仅*在该模块被首次导入时执行。后面的import语句只是简单的创建一个到模块名字空间的引用而已。sys.modules字典中保存着所有被导入模块的模块名到模块对象的映射。这个字典用来决定是否需要使用import语句来导入一个模块的最新拷贝.
from module import * 语句只能用于一个模块的最顶层.*特别注意*:由于存在作用域冲突,不允许在函数中使用from 语句。
每个模块都拥有 __name__ 属性,它是一个内容为模块名字的字符串。最顶层的模块名称是 __main__ .命令行或是交互模式下程序都运行在__main__ 模块内部. 利用__name__属性,我们可以让同一个程序在不同的场合(单独执行或被导入)具有不同的行为,象下面这样做:
# 检查是单独执行还是被导入
if __name__ == '__main__':
# Yes
statements
else:
# No (可能被作为模块导入)
statements
模块搜索路径
导入模块时,解释器会搜索sys.path列表,这个列表中保存着一系列目录。一个典型的sys.path 列表的值:
空字符串 代表当前目录. 要加入新的搜索路径,只需要将这个路径加入到这个列表.
Linux:
['', '/usr/local/lib/python2.0',
'/usr/local/lib/python2.0/plat-sunos5',
'/usr/local/lib/python2.0/lib-tk',
'/usr/local/lib/python2.0/lib-dynload',
'/usr/local/lib/python2.0/site-packages']
Windows:
['', 'C:\\WINDOWS\\system32\\python24.zip', 'C:\\Documents and Settings\\weizhong', 'C:\\Python24\\DLLs', 'C:\\Python24\\lib', 'C:\\Python24\\lib\\plat-win', 'C:\\Python24\\lib\\lib-tk', 'C:\\Python24\\Lib\\site-packages\\pythonwin', 'C:\\Python24', 'C:\\Python24\\lib\\site-packages', 'C:\\Python24\\lib\\site-packages\\win32', 'C:\\Python24\\lib\\site-packages\\win32\\lib', 'C:\\Python24\\lib\\site-packages\\wx-2.6-msw-unicode']
空字符串 代表当前目录. 要加入新的搜索路径,只需要将这个路径加入到这个列表.
模块导入和汇编
到现在为止,本章介绍的模块都是包含Python源代码的文本文件. 不过模块不限于此,可以被 import 语句导入的模块共有以下四类:
•使用Python写的程序( .py文件)
•C或C++扩展(已编译为共享库或DLL文件)
•包(包含多个模块)
•内建模块(使用C编写并已链接到Python解释器内)
当查询模块 foo 时,解释器按照 sys.path 列表中目录顺序来查找以下文件(目录也是文件的一种):
1.定义为一个包的目录 foo
2.foo.so, foomodule.so, foomodule.sl,或 foomodule.dll (已编译扩展)
3.foo.pyo (只在使用 -O 或 -OO 选项时)
4.foo.pyc
5.foo.py
对于.py文件,当一个模块第一次被导入时,它就被汇编为字节代码,并将字节码写入一个同名的 .pyc文件.后来的导入操作会直接读取.pyc文件而不是.py文件.(除非.py文件的修改日期更新,这种情况会重新生成.pyc文件) 在解释器使用 -O 选项时,扩展名为.pyo的同名文件被使用. pyo文件的内容虽去掉行号,断言,及其他调试信息的字节码,体积更小,运行速度更快.如果使用-OO选项代替-O,则文档字符串也会在创建.pyo文件时也被忽略.
如果在sys.path提供的所有路径均查找失败,解释器会继续在内建模块中寻找,如果再次失败,则引发 ImportError 异常.
.pyc和.pyo文件的汇编,当且仅当import 语句执行时进行.
当 import 语句搜索文件时,文件名是大小写敏感的。 即使在文件系统大小写不敏感的系统上也是如此(Windows等). 这样, import foo 只会导入文件foo.py而不会是FOO.PY.
重新导入模块
如果更新了一个已经用import语句导入的模块,内建函数reload()可以重新导入并运行更新后的模块代码.它需要一个模块对象做为参数.例如:
import foo
… some code …
reload(foo) # 重新导入 foo
在reload()运行之后的针对模块的操作都会使用新导入代码,不过reload()并不会更新使用旧模块创建的对象,因此有可能出现新旧版本对象共存的情况。 *注意* 使用C或C++编译的模块不能通过 reload() 函数来重新导入。 记住一个原则,除非是在调试和开发过程中,否则不要使用reload()函数.
二 、包
多个关系密切的模块应该组织成一个包,以便于维护和使用。这项技术能有效避免名字空间冲突。创建一个名字为包名字的文件夹并在该文件夹下创建一个__init__.py 文件就定义了一个包。你可以根据需要在该文件夹下存放资源文件、已编译扩展及子包。举例来说,一个包可能有以下结构:
Graphics/
__init__.py
Primitive/
__init__.py
lines.py
fill.py
text.py
...
Graph2d/
__init__.py
plot2d.py
...
Graph3d/
__init__.py
plot3d.py
...
Formats/
__init__.py
gif.py
png.py
tiff.py
jpeg.py
import语句使用以下几种方式导入包中的模块:
* import Graphics.Primitive.fill 导入模块Graphics.Primitive.fill,只能以全名访问模块属性,例如 Graphics.Primitive.fill.floodfill(img,x,y,color).
* from Graphics.Primitive import fill 导入模块fill ,只能以 fill.属性名 这种方式访问模块属性,例如 fill.floodfill(img,x,y,color).
* from Graphics.Primitive.fill import floodfill 导入模块fill ,并将函数floodfill放入当前名称空间,直接访问被导入的属性,例如 floodfill(img,x,y,color).
无论一个包的哪个部分被导入, 在文件__init__.py中的代码都会运行.这个文件的内容允许为空,不过通常情况下它用来存放包的初始化代码。导入过程遇到的所有 __init__.py文件都被运行.因此 import Graphics.Primitive.fill 语句会顺序运行 Graphics 和 Primitive 文件夹下的__init__.py文件.
下边这个语句具有歧义:
from Graphics.Primitive import *
这个语句的原意图是想将Graphics.Primitive包下的所有模块导入到当前的名称空间.然而,由于不同平台间文件名规则不同(比如大小写敏感问题), Python不能正确判定哪些模块要被导入.这个语句只会顺序运行 Graphics 和 Primitive 文件夹下的__init__.py文件. 要解决这个问题,应该在Primitive文件夹下面的__init__.py中定义一个名字all的列表,例如:
# Graphics/Primitive/__init__.py
__all__ = [“lines”,”text”,”fill”,…]
这样,上边的语句就可以导入列表中所有模块.
下面这个语句只会执行Graphics目录下的__init__.py文件,而不会导入任何模块:
import Graphics
Graphics.Primitive.fill.floodfill(img,x,y,color) # 失败!
不过既然 import Graphics 语句会运行 Graphics 目录下的 __init__..py文件,我们就可以采取下面的手段来解决这个问题:
# Graphics/__init__.py
import Primitive, Graph2d, Graph3d
# Graphics/Primitive/__init__.py
import lines, fill, text, …
这样import Graphics语句就可以导入所有的子模块(只能用全名来访问这些模块的属性).
三、sys.path 和sys.modules
sys.path包含了module的查找路径;
sys.modules包含了当前所load的所有的modules的dict(其中包含了builtin的modules);
Python程序可以调用一组基本的函数(即内建函数),比如print()、input()和len()等函数。Python本身也内置一组模块(即标准库)。每个模块都是一个Python程序,且包含了一组相关的函数,可以嵌入到你的程序之中,比如,math模块包含了数学运算相关的函数,random模块包含随机数相关的函数,等等。
一、import语句
在开始使用一个模块中的函数之前,必须用import语句导入该模块。
语法:
import module1[, module2[,... moduleN]]
实例:
1、使用random模块ranint() 函数:
# printRandom.py import random for i in range(5): print(random.randint(1, 10)) # result:
说明:因randint()函数属于random模块,必须在函数名称之前先加上random,告诉Python在random模块中寻找这个函数。
2、导入多个模块:
import math, sys, random, os
二、from import语句
这是导入模块的另一种形式,使用这种形式的 import 语句, 调用 模块中的函数时不需要 moduleName. 前缀 。但是,使用完整的名称会让代码更可读,所以最好是使用普通形式的 import 语句 。
语法:
from moduleName import name1[, name2[, ... nameN]]|*
实例:
导入random模块下的所有函数:
from random import * for i in range(5): print(randint(1, 10)) # 这里就不需要random.前缀了
导入random模块下的randint, random函数:
from random import randint, random
下面看下python import 和from import 区别
上网查了一下,貌似是一个简单问题,网上都是这么说的,我之前也是这么理解的:
假设有一个包名字叫 numpy, 里面有一个函数 zeros
1、 from numpy import zeros
那么你可以直接调用 zeros()函数
2、import numpy.zeros
那么你只能使用全名 numpy.zeros
但今天遇到了问题了。
from sklearn import datasets a=datasets.load_digits() print(a)
这个代码没问题
但是下面这个代码居然提示错误
import sklearn a=sklearn.datasets.load_digits() print(a)
提示错误是:AttributeError: module ‘sklearn’ has no attribute ‘datasets’
什么鬼,看不懂,不是说import sklearn 后应该可以通过点.来访问sklearn里的所有内容吗,就像numpy中那样。初学者,不懂,求大神解释下,不胜感激!!
这样也报错
import sklearn.datasets a=datasets.load_digits() print(a) NameError: name 'datasets' is not defined
前言
写python肯定会使用很多import 或者是from xxx import AAA
两者到底有什么区别呢?
关键原理
主要是 全局命名空间 的区别,全局命名空间可以用 globals() 函数查看。
全局命名空间虽然叫做全局,但是实际只是模块(一个模块,即是一个python文件)级别的命名空间。
区别表现
- 使用import xxx 到导入的是模块,导入后使用globals()看到xxx模块信息
- 使用from xxx import AAA导入的是对象(函数,类,变量),导入后使用globals()看到AAA信息
比如文件CCC.py:
import AAA from BBB import funcB print globals() funcB()
就会有如下输出:
{
'AAA': < module 'AAA' from 'AAA.pyc' > ,
'funcB': < function funcB at 0x1d9b668 > ,
}
有什么意义?
其实这个时候,funcB,已经是模块CCC里的funcB了. 换句话说,在CCC文件的最后一行调用的funcB,实际是从CCC的全局命名空间里面找到了funcB这个函数。
更深层的说:如果这个时候对 BBB.funcB做出修改或扩展是不能够影响到CCC.funcB的,比如在使用Mock的时候。
常见场景
最常见的情况就是做单元测试的时候。
有文件CCC.py
import AAA
from BBB import funcB
def useFuncB():
return funcB()
def useFuncA():
return AAA.funcA()
现在需要对CCC里面的useFuncB和useFuncA做单元测试,但是AAA和BBB都还没有准备好,mock应该需要出现了
import CCC
class TestCCC(unittest.TestCase):
"""测试CCC"""
def test_userFuncB(self):
"""测试FuncB"""
with mock.patch("BBB.funcB") as mockobj:
mockobj.return_value = "your expect"
self.assertTrue(CCC.useFuncB() == "your expect")
def test_userFuncA(self):
"""测试FuncA"""
with mock.patch("AAA.funcA") as mockobj:
mockobj.return_value = "your expect"
self.assertTrue(CCC.useFuncA() == "your expect")
在如上代码中
- test_userFuncB 总是不能得到如期结果
- test_userFuncA 可以得到如期结果
原因就是: mock对象确实是修改BBB.funcB,但是CCC.useFuncB根本没有使用BBB.funcB,而是使用了CCC.funcB。
怎么办?
减少使用from xxx import BBB,特别是from xxx import * 这样的使用模式。后者将会污染全局命名空间
PS:上文的例子主要是为了介绍原理,并没有完整运行过。