python3我们用pymysql和mysql.connector连接和操作mysql数据库
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2中则使用mysqldb。
PyMySQL 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。
python连接数据库的几种方式
本次代码实现连接远程服务器
由于MySQL服务器以独立的进程运行,并通过网络对外服务,所以,需要支持Python的MySQL驱动来连接到MySQL服务器。
目前,MySQL驱动有几种:
mysql-connector-python:是MySQL官方的纯Python驱动;
MySQL-python:是封装了MySQL C驱动的Python驱动。
安装MySQL驱动:
- pip install mysql-connector-python
测试是否安装成功,测试python下是否可成功导入mysql.connector即可(import mysql.connector)
- pip install MySQL-python (不支持python3)
测试是否安装成功,测试python下是否可成功导入MySQLdb即可(import MySQLdb)
- pip install mysqlclient (mysqlclient 完全兼容MySQLdb,同时支持python3)
测试是否安装成功,测试python下是否可成功导入MySQLdb即可(import MySQLdb)
- pip install PyMySQL
测试是否安装成功,测试python下是否可成功导入pymysql即可(import pymysql)
python连接MySQL数据库的多种方式(方式一)
# 方式一:
import mysql.connector
# 打开数据库连接
db = mysql.connector.connect(host='*.*.*.*',
port=3306,
user='*', # 数据库IP、用户名和密码
passwd='*',
charset = 'utf8')
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("show databases;")
cursor.execute("use database_name;")
cursor.execute("show tables;")
# 使用 fetchone() 方法获取单条数据;使用 fetchall() 方法获取所有数据
data = cursor.fetchall()
for item in data:
print(item[0])
# 关闭数据库连接
db.close()
python连接MySQL数据库的多种方式(方式二)
# 方式二:
import MySQLdb
# 打开数据库连接
conn = MySQLdb.connect(host='*.*.*.*',
port=3306,
user='*',
passwd='*',
charset = 'utf8'
)
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = conn.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("show databases;")
cursor.execute("use database_name;")
cursor.execute("show tables;")
cursor.execute("select * from tables_name")
# 使用 fetchone() 方法获取单条数据;使用 fetchall() 方法获取所有数据
data = cursor.fetchall()
for item in data:
print(item)
# 关闭数据库连接
cursor.close()
python连接MySQL数据库的多种方式(方式三)
# 方式三:
import pymysql
# 打开数据库连接
conn = pymysql.connect(host='*.*.*.*',
port=3306,
user='*',
passwd='*',
charset = 'utf8'
)
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = conn.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("show databases;")
cursor.execute("use database_name;")
cursor.execute("show tables;")
cursor.execute("select * from tables_name")
# 使用 fetchone() 方法获取单条数据;使用 fetchall() 方法获取所有数据
data = cursor.fetchall()
for item in data:
print(item[0])
# 关闭数据库连接
cursor.close()
python对MySQL增删改查
一、基本操作
(1) 查询
import pymysql conn = pymysql.connect(host='127.0.0.1', user='root', passwd='root', db='test') cur = conn.cursor() # 查询 sql = "select * from info" reCount = cur.execute(sql) # 返回受影响的行数 print(reCount) data = cur.fetchall() # 返回数据,返回的是tuple类型 print(data) """ ((1, 'mj', 'tokyo'), (2, 'alex', 'newyork'), (3, 'tommy', 'beijing')) """ cur.close() conn.close()
(2) 修改
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', passwd='root', db='test')
cur = conn.cursor()
# 插入数据
sql2 = "insert into info(NAME,address ) VALUES(%s,%s)" # sql语句,%s是占位符(%s是唯一的,不论什么数据类型都使用%s)用来防止sql注入
params = ('eric', 'wuhan') # 参数
reCount = cur.execute(sql2, params)
# 批量插入
li = [('a1', 'b1'), ('a2', 'b2')]
sql3 = 'insert into info(NAME ,address) VALUES (%s,%s)'
reCount = cur.executemany(sql3, li)
conn.commit() # 提交,执行多条命令只需要commit一次就行了
cur.close()
conn.close()
(3) 返回dict类型的数据
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', passwd='root', db='test')
# cur = conn.cursor()
cur = conn.cursor(cursor=pymysql.cursors.DictCursor) #创建cursor的时候,指定1其返回的cursor类型为dict
# 查询
sql = "select * from info"
reCount = cur.execute(sql) # 返回受影响的行数
print(reCount)
data = cur.fetchall() # 返回数据,返回的是tuple类型
print(data)
cur.close()
conn.close()
"""
[{'address': 'tokyo', 'name': 'mj', 'id': 1}, {'address': 'newyork', 'name': 'alex', 'id': 2}, {'address': 'beijing', 'name': 'tommy', 'id': 3}]
"""
(4)获取自增id
通过cur.lastrowid来获取自增id
# 插入数据
sql = "insert into info(NAME,address ) VALUES(%s,%s)"
params = ('eric', '/usr/bin/a.txt')
reCount = cur.execute(sql, params)
conn.commit()
new_id = cur.lastrowid #获取自增id,提交完之后才能取到值
print(new_id)
(5)插入数据
插入数据使用 “INSERT INTO” 语句:
demo_mysql_test.py:
向 sites 表插入一条记录。
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="runoob_db"
)
mycursor = mydb.cursor()
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = ("RUNOOB", "https://www.runoob.com")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")
(6)删除记录
删除记录使用 “DELETE FROM” 语句:
demo_mysql_test.py
删除 name 为 stackoverflow 的记录:
import mysql.connector mydb = mysql.connector.connect( host="localhost", user="root", passwd="123456", database="runoob_db" ) mycursor = mydb.cursor() sql = "DELETE FROM sites WHERE name = 'stackoverflow'" mycursor.execute(sql) mydb.commit() print(mycursor.rowcount, " 条记录删除")
二、cursor定位
使用fechone来逐条获取数据
data = cur.fetchone() print(data) data = cur.fetchone() print(data) data = cur.fetchone() print(data) """ (1, 'mj', 'tokyo') (2, 'alex', 'newyork') (3, 'tommy', 'beijing') """
(1) 绝对定位
cur.scroll(0,mode='absolute')
data = cur.fetchone() print(data) cur.scroll(0,mode='absolute') data = cur.fetchone() print(data) data = cur.fetchone() print(data) """ (1, 'mj', 'tokyo') (1, 'mj', 'tokyo') (2, 'alex', 'newyork') """
(2) 相对定位
cur.scroll(-1,mode='relative')
data = cur.fetchone() print(data) data = cur.fetchone() print(data) cur.scroll(-1,mode='relative') data = cur.fetchone() print(data) """ (1, 'mj', 'tokyo') (2, 'alex', 'newyork') (2, 'alex', 'newyork') """
三、解耦
这里简单实现一个用户登录的功能,以便对整个业务结构有一个整体的认识。
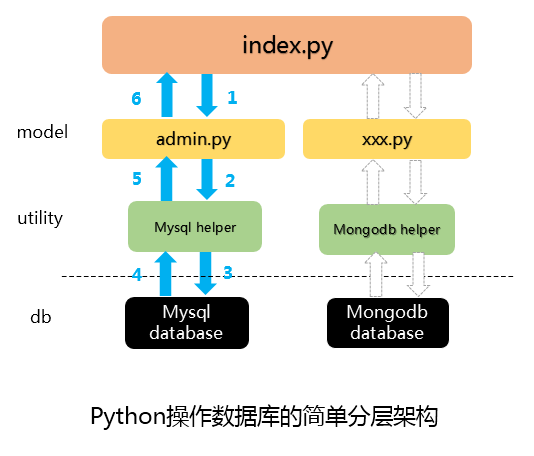
项目目录结构
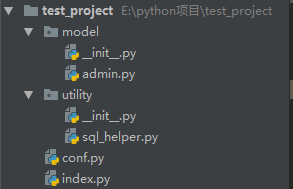
index.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from model.admin import Admin
def main():
usr = input("username:")
pwd = input("password:")
admin = Admin()
result = admin.CheckValidate(usr, pwd)
if not result: # 一般会把简单的逻辑放在上面,复杂的逻辑放下面
print("登录失败!")
else:
print("登陆成功!进入后台管理界面..")
if __name__ == "__main__":
main()
admin.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from utility.sql_helper import MySqlHelper
class Admin():
def __init__(self):
self.__helper = MySqlHelper()
def CheckValidate(self,username,password):
sql = "select * from admin where username=%s and password=%s"
params=(username,password)
return self.__helper.getOne(sql,params)
sql_helper.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import pymysql
import conf
class MySqlHelper(object):
def __init__(self):
self.__conn_dict = conf.conn_dict # 把数据库连接信心提取到conf中
def getDict(self, sql, params):
conn = pymysql.connect(**self.__conn_dict)
cur = conn.cursor(cursor=pymysql.cursors.DictCursor)
cur.execute(sql, params)
data = cur.fetchall()
cur.close()
conn.close()
return data
def getOne(self, sql, params):
conn = pymysql.connect(**self.__conn_dict) # 加**后表示传入的是字典里的数据,否则报错
cur = conn.cursor(cursor=pymysql.cursors.DictCursor)
cur.execute(sql, params)
data = cur.fetchone()
cur.close()
conn.close()
return data
conf.py
#!/usr/bin/env python3 # -*- coding:utf-8 -*- conn_dict = dict(host='127.0.0.1', user='root', passwd='root', db='test')
python对mysql的操作的三种实现方式。
再此之前先引入三个知识点:
1 :__name__==’__main__’
这是什么意思呢?
1.python文件的后缀为.py
2..py文件既可以用来直接执行,也可以用来作为模块被导入,
3.在python中用import导入模块
__name__作为模块的内置属性,简单点说,就是.py文件的调用方式,如果是以模块调用__name__就等于该模块的名字(后文会继续说明),如果是直接调用__name__就等于’__main__’
2:命令行传参
何为命令行传参? 顾名思义 ,是在命令行传递参数,和常见的传递参数方式不同的是,命令行传递参数是把参数和程序写在同一个命令行来运行。
给个实际的图片看一下(我用的是linux环境,如果在windows下可用dos实现):

这里python3 是执行python程序的格式,pyt3.py 和pyt2.py是 .py程序的名字,而后面的 100 101 3都是参数。
明确了这个之后,引入一个库,sys库,这个库可以支持对命令行传递过来的参数的一些操作(后文会继续说明)。
3:pymysql这个库
注意,在python3以上版本已经不支持mysqldb这个库了,不过两者的方法基本相同。
这个库的用法主要步骤如下:
1:建立connection
2:获取cursor(可以把它当做一个游标)
3:执行sql语句
4:事务出现异常?
n:con.commit
y:con.rollback
5:获取执行sql后的数据
cursor.fetch
这里提到了事务,事务又是什么呢。简单的说,一个事务包含的所有操作都是原子操作 即 要么都执行 要么都不执行,事务有什么用呢(后文会继续说明)
好了,回归正题,那么python操作mysql数据库有哪三种方式呢? 以银行转账为例,先看第一种
1:普通方式
import pymysql
import sys
con=pymysql.Connect(host='xxx.xxx.xx.xx',port=3306,db='pytest',user='root',
passwd='xxx',charset='utf8')
cursor=con.cursor()
def is_ava(acctid):
sel_sql='select * from account where acctid=%s'%acctid
cursor.execute(sel_sql)
rs=cursor.fetchone()
try:
len(rs)
except:
return False
return True
def mon_ava(acctid,mon):
selm_sql='select *from account where acctid=%s and money>=%s'%(acctid,mon)
cursor.execute(selm_sql)
rs=cursor.fetchone()
try:
len(rs)
except:
return False
return True
sr_id=sys.argv[1]
tr_id=sys.argv[2]
dt_money=sys.argv[3]
if is_ava(sr_id) and is_ava(tr_id):
if mon_ava(sr_id,dt_money):
rm_sql=' update account set money=money-%s where acctid=%s'%(dt_money,sr_id)
add_sql=' update account set money=money+%s where acctid=%s'%(dt_money,tr_id)
try:
cursor.execute(rm_sql)
cursor.execute(add_sql)
con.commit()
except:
con.rollback()
finally:
cursor.close()
con.close()
这里纯粹是面向过程的编程思想,注意代码最后的try ,except 这里就是一个完整的事务流程,当执行remove 和add出现了异常 就进行rollback()rollback的作用就是回滚到sql语句执行前的状态。
为什么要这样呢? 试想这种情况:A给B的银行卡转账100块钱,即A-100 B+100.而B在此之前把此银行卡注销掉了, 如果不进行事务操作 就会出现:A白白丢失100块钱的情况
而我们期望的情况是这样:A-100 B+100 ,如果转账过程中出现了异常,A、B的金额都保持不变。使用事务这种原子性操作就可以确保操作的安全。
2:下面看第二种方法 面向对象方式:
# -*- coding: utf-8 -*-
import pymysql
import sys
class TransforMoney(object):
def __init__(self,con):
self.con=con
self.cursor=self.con.cursor()
def is_ava(self,acctid):
sel_sql='select * from account where acctid=%s'%acctid
self.cursor.execute(sel_sql)
rs=self.cursor.fetchone()
try:
len(rs)
except:
raise Exception
def mon_ava(self,acctid,mon):
selm_sql='select *from account where acctid=%s and money>=%s'%(acctid,mon)
self.cursor.execute(selm_sql)
rs=self.cursor.fetchone()
try:
len(rs)
except:
raise Exception
def rd_mon(self,acctid,mon):
rm_sql=' update account set money=money-%s where acctid=%s'%(mon,acctid)
self.cursor.execute(rm_sql)
if self.cursor.rowcount != 1:
raise Exception
def add_mon(self,acctid,mon):
add_sql=' update account set money=money+%s where acctid=%s'%(mon,acctid)
self.cursor.execute(add_sql)
if self.cursor.rowcount != 1:
raise Exception
def transfor(self,srid,trid,mon):
try:
self.is_ava(srid)
self.is_ava(trid)
self.mon_ava(srid,mon)
self.rd_mon(srid,mon)
self.add_mon(trid,mon)
self.con.commit()
except:
self.con.rollback()
finally:
self.cursor.close()
self.con.close()
if __name__=='__main__':
sr_id=sys.argv[1]
tr_id=sys.argv[2]
dt_money=sys.argv[3]
con=pymysql.Connect(host='xxx.xxx.xx.xx',port=3306,db='pytest',user='root',
passwd='xxxxx',charset='utf8')
tr_obj=TransforMoney(con)
tr_obj.transfor(sr_id,tr_id,dt_money)
把所有方法都封装到一个类里,transfor方法里同样是事务操作,前面也说道过 __name__这个内置属性,这个程序如果直接运行的话 __name__就等于__main,那么此时if __name__==’__main__’ 就成立,即这句话相当于该程序的入口。
3:下面看第三种方式 模块化
# -*- coding: utf-8 -*-
"""
Created on Tue Jun 6 11:45:42 2017
@author: A
"""
import sys
import pymysql
import temp2
sr_id=sys.argv[1]
tr_id=sys.argv[2]
dt_money=sys.argv[3]
con=pymysql.Connect(host='xxx.xxx.xx.xx',port=3306,db='pytest',user='root',
passwd='xxxxx',charset='utf8')
tr_obj=temp2.TransforMoney(con)
tr_obj.transfor(sr_id,tr_id,dt_money)
是不是很短,没错,把上述第二种方式的程序保存为temp2.py ,在该程序里直接import temp2 即可调用temp2.py的类的方法,注意此时temp2.py里的__name__ 就不等于__main__了 而是等于 temp.
对了,以上的连接 host 和 passwd 我都用xxx 来表示了,因为是我个人的服务器不便于公开,实际中大家改成自己的就可以了。