#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/*经常会遇到编译不出错,运行出错的情况,现做简要分析*/
int main()
{
/*1.使用了不该使用的内存*/
int a[5]={0};
//一.a[6]=8;//编译器并不会报错,因为所有的下标只是指针的偏移,但是a[4]以后的内存系统并未分配给程序员使用
char b[]={'h','e','l','l','o'};
char c[1000];
strcpy (c,b);
printf ("%s",c);
/*strcpy等操作字符串的函数只在检测到'\0'时才结束,所以b[4]后面什么时候遇到'\0'是未知的,而且更大的可能是遇到值大于127的内存单元,因为char是有符号的,就会变成负数,从而根据unicode的显示规则来显示*/
char* d=(char*)malloc(100);
char* e=d;
free(e);
scanf ("%s",d);
/*两个指针指向同一块内存,当一个指针释放了内存后,再使用另一个指针对这块内存进行操作可能会导致程序奔溃*/
/*2.改变了不能改变区域的内容*/
char *f="asdfg";
scanf("%s",f);
/*f指向的存储在常量空间的常量字符串,不能改变这片区域上存储的内容。*/
/*3.内存管理问题*/
char* g=(char*)malloc(100);
char *h=g;
free(g);
free(h);
/*两个指针指向同一块动态内存,但是一块内存只能释放一次,对同一块内存释放两次程序会崩*/
char i[100];
free (i);
/*只有动态内存可以释放,自动变量由系统进行管理,对其进行free会导致未知错误*/
return 0;
}
//tianqiweiqi.com
C++编译错误与运行时错误
笔试题里经常会有这样的题目,让你判断运行时错误还是编译错误。在这里将它总结一下。
在调试过程中,运行时错误是最麻烦的问题。因为编译错误可以由编译器检查出来,而大多数编译器对运行时错误却无能为力。查错和纠错的工作完全由用户自己来完成。
运行时错误还分为两种:
1、一种是由于考虑不周或输入错误导致程序异常(Exception),比如数组越界访问,除数为零,堆栈溢出等等。
2、另一种是由于程序设计思路的错误导致程序异常或难以得到预期的效果。
需要注意的是,一个重要的运行时错误是:使用失效的迭代器
对于第一类运行时错误,我们不需要重新设计解决问题的思路,认为当前算法是可行的、有效的。我们只需要找出输入的错误或考虑临界情况的处理方法即可。
对于第二类运行时错误,不得不遗憾地说,一切都要从头再来。
语法错误的位置能很快地被编译器找到,而运行时错误的位置却很难被我们发现。即使我们一条条地检查语句,也未必能检查出什么。
什么样的是运行时错误?
由于编译器无法发现运行时错误,这些错误往往是在程序运行时以五花八门的形式表现出来。下面就是典型的几种因运行时错误引起的问题:
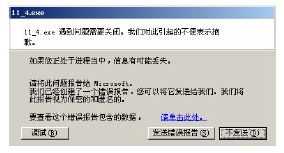
(1)WindowsXP错误报告
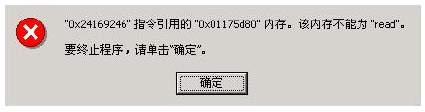
(2)内存不能为Read/Written
(3)非法操作

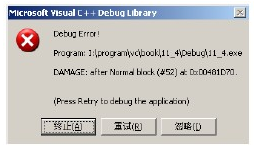
(4)Debug错误
出错总有原因 之 写在前面
写这部分主要是总结一下自己工作中遇到的一些错误问题以及解决办法,大部分都不是些什么了不得的问题,即使某些问题看上去很奇怪,但其实都是有迹可循的,有些甚至是一些明显的错误引起的。
当然,我也不是对于每个问题都能寻根究底,而且有些问题的记忆也不是那么清晰了,或者,当初的记录并没有细致的去截取堆栈信息的图表之类,主要是记下来作为自己的参考,避免以后犯同样的错误,这就是所谓的工作经验吧!
出错总有原因 之 匆忙引入多线程引发的Crash
一年之前,考虑到性能问题,需要引入多线程的工作机制来将数据备份到云存储上,但是时间要求得非常急迫,而原有代码完全是处于年久失修的状况,根本来不及重新设计,于是只有在原来的基础上开辟多个线程,每个线程上传一个文件。每个线程都有自己的文件对象,看上去好像各个线程间没有共享什么对象,每个线程所用到的日志类也是线程安全的,看上去问题不大。
但实际测试中还是发生了Crash,可奇怪的是,只有在客户机器那里才会出现。
拿到Dump后才发现,虽然每个线程都使用了自己的文件对象,但是各个文件对象共用了同一份Cache,这个Cache用来记录访问过的文件Id以提升性能,避免频繁的去服务器查询Id,这个Cache组织成为一个Map,是需要加锁的,否则多个线程同时访问一个Map肯定是会出问题的。文件类是很久以前写好的,并没有考虑过线程安全的问题,所以自然就会出现Crash的问题啦!
搞笑的是,测试人员不认为存在问题,因为他们无论如何也重现不了这个Bug。代码中明显存在的问题,按道理应该很容易重现才对。我加了一些OutputDebugString语句在DbgView中输出才发现,由于云服务器在国外,国内网速很慢,所以各个线程每次从服务器取到文件Id都刚好存在一个时间差,于是导致将这些信息存入Cache的时候也存在一个时间差,居然在绝大多数情况下不会同时进入到同一个函数中去,从而也导致这个问题发生的概率很低。
而报出Bug来的客户是在美国,网速快得多,会有更大几率同时调用存取Cache的函数,在没有加锁的情况下,就更容易出现Crash啦!
经验教训:引入多线程机制的时候,一定要仔细查看底层类是否是线程安全的。
出错总有原因 之第三方库不一定可靠啊
某年某月的某一天,测试人员发现我们的程序运行起来后发生了一次Crash, 但是无论如何也无法重现,也没有明显步骤,就是开始运行就Crash了,而且由于是C#的代码,Dump里面也没有多少有意义的信息,于是不了了之。
正式发布之后,不停的有客户出现类似的问题。Dump不管用,只能从系统日志中收集到一些错误信息,比如发生Crash的模块和Offset等等,通过编译时候生成的Map文件终于定位到了问题是发生在一个Intel提供的第三方库里面(具体的方法另写文章再讲)。而问题的原因其实很简单,这个第三方库是由C++写成的,但是在使用指针的时候根本就没有做判空检查,所有的指针都没有做判空检查。这个库是用来扫描UPNP设备的,我们的程序在启动的时候就开始扫描UPNP设备,正常情况下不会有问题,但是由于UPNP设备是各种各样的,有可能会取不到正确的信息,在取不到正确的信息的时候,很多指针都是NULL,如果在使用前不做检查,自然就容易Crash了!
而正是因为我们迷信这是Intel提供的第三方库,而且这个库本身非常复杂,将这个类库引入我们Solution的工程也就没有深入研究,从而导致了这个严重的问题。
可见,防御性编程是多么的重要啊!
出错总有原因 之 工程每次都重新编译
使用VSTS2010编译的时候,偶尔遇到某些工程,明明已经编译过了的,但是选择编译整个Solution的时候,却没有忽略这些Project,而将这些Project还是原样重新编译过一次。
这里主要讲讲自己遇到过的情况以防大家遇到类似的问题。
其中一个原因是,自己修改了系统时间做一些功能的测试,在系统时间修改之后,又做了代码的修改。譬如说,先将时间改到了一周之后,做了测试,发现了问题,立马做了代码的修正,然后继续测试,测试没问题了自己继续工作。可是系统时间后来同步到了正确的时间,于是编译的时候,编译器发现有个CPP文件的改动时间是新于dll或者exe生成的时间,自然就会认为是新的改动,于是就会每次重新编译啦。
另外一种情况是,某个头文件加入到了工程之中,但是后来改动中发现,并不需要这个头文件,于是从本地删除了这个头文件,而且去除了所有包含这个头文件的地方,但是忘记从工程中删除这个头文件了,在这种情况下,VSTS2010也会每次重新编译这个工程的。
那么,如何找出问题所在呢?
其实很简单,在VSTS2010的菜单项Tools–>Options–>Projects and Solutions–>Build and Run中,里面可以设置”MSBuild project build output verbosity”和”MSBuild project build log file verbosity”的级别,从Normal改为Detailed便可以从Output或者编译日志中获得更多信息;如果需要更详细信息的话,还可以将这个级别设置成为Diagnostic呢,不过一般情况下,Diagnostic包含的更详细信息没有什么特别的意义。
题外话,关于修改时间导致的编译问题,我遇到过的另外一种情况就是,做了改动,也编译成功了,但是实际运行的时候改动没有生效,断点也和当前代码不一致。而问题出在这个dll是在我改动时间之后编译成功的;当时间同步会当前时间后,虽然修改了代码,但是并没有替换掉更新的那个dll;这个时候,只需要Clean掉,重新编译即可。
出错总有原因 之 关于重新编译
在开发过程中,偶尔遇到这样的问题,程序运行不正常或者改动没有生效,Clean掉,重新编译,然后重新运行就好了;但有几次,程序工作得好好的,重新编译过后,就无法正确运行起来了,这是编译器的魔法吗?
显然不是。程序工作不工作,都是有原因的,肯定不是什么魔法。
我在实际工作中遇到的重新编译后程序就可以正常运行,往往是这么几种情况,第一种情况,最初的编译过程只编译了改动的静态库,但是对于可执行文件并没有强制的重新编译,所以仍然会调用原来代码,改动自然不会生效啦;在这种情况下,只要弄清楚了自己工程的依赖关系,重新编译指定的工程,自然就可以解决问题了;第二种情况就不常见了,有的时候调试进去发现代码和Symbols根本不对应,根本就没有跳转到指定的代码中去,甚至无法加断点,这种情况下,往往是加载的dll与代码不匹配或者相应的Symbol信息未加载到调试器,这个时候就需要全部Clean掉,然后重新编译,保证生成正确的dll组件啦。
而在我们工作中出现的重新编译过后无法正确运行的问题是什么呢,原因是因为我们会用到公司提供的一些公共组件,如果强制全部重新编译,会去根据配置文件获取指定版本的公共组件,如果永远是指定使用最新的版本,但是会去重新获取最新版本的公共组件,但是如果自己的代码没有相应的调整或者说公共组件存在某些问题的话,自然就无法运行起来啦。
感悟:重新编译是解决某些问题的利器,但要想无往而不利,最好的办法是弄清楚编译过程中究竟做了哪些事情,编译前有没有执行哪些脚本来生成一些公共的头文件,编译后又有没有执行某些脚本来拷贝公共组件或者是注册某些公共组件呢?所以,所有工作的核心都是深入了解其工作原理,代码如是,编译过程亦如是。
出错总有原因 之 仅有第一次编译不成功
新人入职,取下项目代码,打开VSTS2010, 编译整个Solution,第一次编译不成功,提示Link错误,某个Lib未找到。但这个问题在其他开发机器上并没有出现过。在第一次编译的基础上再次编译,成功了。
检查第一次编译出错的日志,发现出错的dll依赖于提示的library,这个library是在dll之前编译的,这个顺序是没错的。但是从日志中可以看到,原来是由于并行编译引起的。根据依赖关系,被依赖的library先编译,但是由于并行编译的设置,dll也在稍后开始编译,那么如果dll的编译进程执行速度足够快,在链接之前可能对应的library还没有编译成功,这样就会出现这个问题了。
一般而言,在开发机器上,这不能算是个问题,因为第二次编译过程中仍然会成功的。
如果是专门做安装包的机器,还是有必要设置一下的。就在菜单Tools–>Options–>Projects and Solutions–>Build and Run下面,可以指定“maximum number of parallel project builds”,如果指定为1,那么就不会有并行编译了。
当然,如果一直只有一个编译过程进行仍然出现类似的链接错误的话,就要仔细检查依赖关系是否正确啦!