更多:开源围棋…
链接: https://pan.baidu.com/s/1v0VDqjQOyBvjLIJrZbUn4w 提取码: sd4s
GitHub
https://github.com/billchiles/sgfeditor
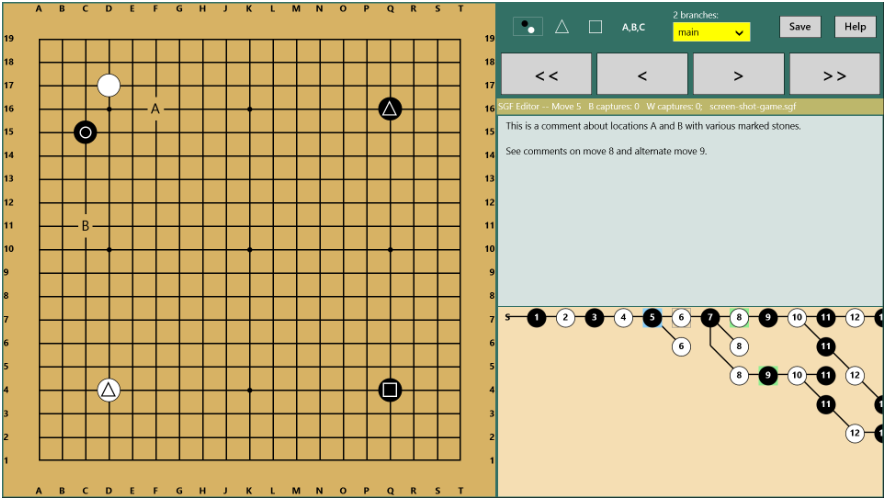
包含C#写的围棋GUI界面。
还有python版本的sgf编辑
//// sgfparser.cs parses .sgf files. Each parse takes a file and creates a list
//// of ParsedNodes. The list of nodes may not adhere to normal game moves such
//// as alternating colors, or starting with B in an even game and W with
//// handicaps. The first node is the root node and should be game properties
//// while following nodes should represent a game, but the nodes could
//// represent setup for a problem.
////
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Text.RegularExpressions;
namespace SgfEd {
public class ParsedGame {
public ParsedNode Nodes { get; set; }
public ParsedGame () {
// nodes is the only public member.
this.Nodes = null;
}
//// __str__ produces a strong that when printed to a file generates a valid
//// .sgf file.
////
public override string ToString () {
if (this.Nodes == null)
return ""; // Min tree is "(;)", but that implies one empty node
else
return "(" + this.NodesString(this.Nodes) + ")";
}
//// _nodes_string returns a string for a series of nodes, and the caller
//// needs to supply the open and close parens that bracket the series.
////
private string NodesString (ParsedNode nodes) {
var res = "";
while (nodes.Next != null) {
// Get one node's string with a leading newline if it is not the
// first.
res += nodes.NodeString(res != "");
if (nodes.Branches != null) {
foreach (var n in nodes.Branches)
res = res + "\n(" + this.NodesString(n) + ")";
return res;
}
nodes = nodes.Next;
}
res += nodes.NodeString(res != ""); // Test res, could be single node branch.
return res;
}
} // ParsedGame class
public class ParsedNode {
public ParsedNode Next;
public ParsedNode Previous;
public List<ParsedNode> Branches;
public Dictionary<string, List<string>> Properties;
public ParsedNode() {
this.Next = null;
this.Previous = null;
this.Branches = null;
this.Properties = new Dictionary<string, List<string>>();
}
//// node_str returns the string for one node, taking a flag for a
//// preceding newline and the dictionary of properties for the node.
//// Game uses this for error reporting.
////
public string NodeString(bool newline) {
var props = this.Properties;
string s;
if (newline)
s = "\n;";
else
s = ";";
// Print move property first for readability of .sgf file by humans.
if (props.ContainsKey("B"))
s = s + "B" + this.EscapePropertyValues("B", props["B"]);
if (props.ContainsKey("W"))
s = s + "W" + this.EscapePropertyValues("W", props["W"]);
foreach (var kv in props) {
var k = kv.Key;
if (k == "B" || k == "W") continue;
s = s + k + this.EscapePropertyValues(k, kv.Value);
}
return s;
}
//// _escaped_property_values returns a node's property value with escapes so that the .sgf
//// is valid. So, ] and \ must be preceded by a backslash.
////
private string EscapePropertyValues(string id, List<string> values) {
var res = "";
foreach (var v in values) {
res = res + "[";
if (v.Contains(']') || v.Contains('\\')) {
var sb = new StringBuilder();
foreach (var c in v) {
if (c == ']' || c == '\\')
sb.Append('\\');
sb.Append(c);
}
res = res + sb.ToString() + "]";
}
else
res = res + v + "]";
} //foreach
return res;
}
} // ParsedNode class
//// ParserAux provides stateless helpers for parsing. Public members are used throughout
//// the program.
////
public class ParserAux {
public static ParsedGame ParseFile (string name) {
var l = new Lexer(File.ReadAllText(name));
l.ScanFor("(", "Can't find game start");
var g = new ParsedGame();
g.Nodes = ParseNodes(l);
return g;
}
//// _parse_nodes returns a linked list of ParseNodes. It starts scanning for a
//// semi-colon for the start of the first node. If it encounters an open
//// paren, it recurses and creates branches that follow the current node,
//// making the next pointer of the current node point to the first node in the
//// first branch.
////
private static ParsedNode ParseNodes (Lexer lexer) {
lexer.ScanFor(";", "Must be one node in each branch");
var cur_node = ParseNode(lexer);
var first = cur_node;
var branching_yet = false;
while (lexer.HasData()) {
// Semi-colon starts another node, open paren starts a branch, close
// paren stops list of nodes. Scanning raises an exception if one of
// these chars fails to follow (ignoring whitespace).
var chr = lexer.ScanFor(";()");
if (chr == ';') {
if (branching_yet)
throw new Exception("Found node after branching started.");
cur_node.Next = ParseNode(lexer);
cur_node.Next.Previous = cur_node;
cur_node = cur_node.Next;
}
else if (chr == '(') {
if (! branching_yet) {
cur_node.Next = ParseNodes(lexer);
cur_node.Next.Previous = cur_node;
cur_node.Branches = new List<ParsedNode>() { cur_node.Next };
branching_yet = true;
}
else {
var n = ParseNodes(lexer);
n.Previous = cur_node;
cur_node.Branches.Add(n);
}
}
else if (chr == ')')
return first;
else
throw new FileFormatException("SGF file is malformed at char " + lexer.Location.ToString());
}
throw new FileFormatException("Unexpectedly hit EOF!");
} // ParseNodes
//// _parse_node returns a ParseNode with its properties filled in.
////
private static ParsedNode ParseNode (Lexer lexer) {
var node = new ParsedNode();
// Loop properties ...
while (lexer.HasData()) {
var id = lexer.GetPropertyId();
if (id == null)
// Expected to return from here due to no properties or syntax at end of properties.
return node;
if (node.Properties.ContainsKey(id))
throw new Exception(string.Format("Encountered ID, {0}, twice for node -- file location {1}.",
id, lexer.Location));
lexer.ScanFor("[", "Expected property value");
var i = -1;
var values = new List<string>();
node.Properties[id] = values;
// Loop values for one property
while (lexer.HasData()) {
// C and GC properties allow newline sequences in value.
values.Add(lexer.GetPropertyValue(id == "C" || id == "GC"));
i = lexer.PeekFor("[").Item1;
if (i == -1) break; // no new values
lexer.Location = i;
}
}
throw new FileFormatException("Unexpectedly hit EOF!");
} // ParseNode
} // ParserAux Class
//// The Lexer class provides stateless helpers for Parser or ParserAux.
////
internal class Lexer {
private string _data;
private int _data_len;
private int _index;
internal Lexer (string contents) {
this._data = contents;
this._data_len = contents.Length;
this._index = 0;
}
internal int Location { get {return this._index;}
set {this._index = value;} }
//// scan_for scans for any char in chars following whitespace. If
//// non-whitespace intervenes, this is an error. Scan_for leaves _index
//// after char and returns found char.
////
internal char ScanFor(string chars, string errmsg = null) {
var tmp = this.PeekFor(chars);
var i = tmp.Item1;
var c = tmp.Item2;
if (i == -1) {
if (errmsg != null)
errmsg = errmsg + " -- file location " + this._index.ToString();
throw new Exception(errmsg ?? string.Format("Expecting one of '{0}' while scanning -- file location {1}",
chars, this._index));
}
else {
this._index = i;
return c;
}
}
//// peek_for scans for any char in chars following whitespace. If
//// non-whitespace intervenes, this is an error. Scan_for leaves _index
//// unmodified.
////
internal Tuple<int, char> PeekFor(string chars) {
var i = this._index;
while (this.HasData()) {
var c = this._data[i];
i += 1;
if (" \t\n\r\f\v".Contains(c))
continue;
else if (chars.Contains(c))
return new Tuple<int, char>(i, c);
else
return new Tuple<int, char>(-1, ((char)0));
}
return new Tuple<int, char>(-1, ((char)0));
}
internal bool HasData() {
return this._index < this._data_len;
}
private Regex propertyIdRegexp = new Regex(@"\s*([A-Za-z]+)");
//// get_property_id skips any whitespace and expects to find alphabetic chars
//// that form a property name. .NET does not match at start location by default.
//// .NET returns extra groups, and naming the one group in the pattern does not help find group.
//// This empirically assumes groups[1] is the group we want, no documentation on group[0] in .NET,
//// but it appears to be the whole match, which lets us test if we matched at the start or not.
////
internal string GetPropertyId () {
var match = this.propertyIdRegexp.Match(this._data, this._index);
if (match.Success && match.Groups[0].Index == this._index) {
this._index += match.Length;
return match.Groups[1].ToString();
}
return null;
}
//// get_property_id skips any whitespace and expects to find alphabetic chars
//// that form a property name. This function open codes a simple regexp that
//// .NET matches incorrectly. .NET fails to match at the start index provided
//// in two ways. It finds any match anywhere in the string, which is arguably
//// appropriate, but when you use the match start syntax and provide a start
//// index for searching, .NET always fails the match.
////
//internal string GetPropertyId () {
// var i = this._index;
// // Skip any whitespace
// while (i < this._data_len) {
// var c = this._data[i];
// if (" \t\n\r\f\v".Contains(c)) {
// i += 1;
// continue;
// }
// else
// break;
// }
// // Grab alphabetic chars or fail
// var sb = new StringBuilder();
// while (i < this._data_len) {
// var c = this._data[i];
// if (('a' <= c && 'z' >= 'c') || ('A' <= c && 'Z' >= c)) {
// i += 1;
// sb.Append(c);
// }
// else
// break;
// }
// if (sb.Length > 0) {
// this._index = i;
// return sb.ToString();
// }
// else
// return null;
//}
//// get_property_value takes a flag as to whether un-escaped newlines get
//// mapped to space or kept as-is. It gobbles all the characters after a
//// '[' (which has already been consumed) up to the next ']' and returns
//// them as a string. Keep_newlines distinguishes properties like C and GC
//// that can have newlines in their values, but otherwise, newlines are
//// assumed to be purely line-length management in the .sgf file.
////
//// SGF "text" properties can have newlines, newlines following \ are removed
//// along with the \, other escaped chars are kept verbatim except whitespace
//// is converted to space.
////
//// SGF "simpletext" properties are the same as "text" but have no newlines.
////
internal string GetPropertyValue(bool keep_newlines) {
var res = new StringBuilder();
while (this.HasData()) {
var c = this._data[this._index];
this._index += 1;
if (((int)c) < ((int)' ')) { //if < space
// Map whitespace to spaces.
var tmp = this.CheckPropertyNewline(c);
var newline = tmp.Item1;
var c2 = tmp.Item2;
if (newline)
// Only map newline sequences according to keep_newlines.
if (keep_newlines) {
// Canonicalize newlines because 1) would write mixed newline sequences in different places
// in .sgf depending on comments vs. other syntax, and 2) winRT textbox converts all line
// endings with no option to preserve them. Not needed for WPF, but doesn't hurt.
res.Append('\r');
res.Append('\n');
}
else
res.Append(" "); //convert newline to space to separate words
else
res.Append(" "); //convert whatever whitespace it was to space
}
else if (c == '\\') {
// Backslash quotes chars and erases newlines.
c = this._data[this._index];
this._index += 1;
var newline = this.CheckPropertyNewline(c).Item1;
if (! newline)
res.Append(c);
}
else if (c == ']')
return res.ToString();
else
res.Append(c);
}
throw new FileFormatException("Unexpectedly hit EOF!");
} // GetPropertyValue
//// _check_property_newline check if c is part of a newline sequence. If
//// it is, then see if there's a second newline sequence char and gobble
//// it. Returns whether there was a newline sequence and what the second
//// char was if it was part of the newline sequence.
////
private Tuple<bool, char> CheckPropertyNewline (char c) {
if (c == '\n' || c == '\r') {
// Only map newline sequences according to keep_newlines.
var c2 = this._data[this._index];
if (c2 == '\n' || c2 == '\r') {
this._index += 1;
return new Tuple<bool, char>(true, c2);
}
return new Tuple<bool, char>(true, ((char)0));
}
else
return new Tuple<bool, char>(false, ((char)0));
}
} // Lexer class
} // namespace