
第5章 深度学习用于计算机视觉
本章包括以下内容:
- 理解卷积神经网络(convnet)
- 使用数据增强来降低过拟合
- 使用预训练的卷积神经网络进行特征提取
- 微调预训练的卷积神经网络
- 将卷积神经网络学到的内容及其如何做出分类决策可视化
本章将介绍卷积神经网络,也叫 convnet,它是计算机视觉应用几乎都在使用的一种深度学习模型。你将学到将卷积神经网络应用于图像分类问题,特别是那些训练数据集较小的问题。如果你工作的地方并非大型科技公司,这也将是你最常见的使用场景。
5.1 卷积神经网络简介
我们将深入讲解卷积神经网络的原理,以及它在计算机视觉任务上为什么如此成功。但在此之前,我们先来看一个简单的卷积神经网络示例,即使用卷积神经网络对 MNIST数字进行分类,这个任务我们在第 2章用密集连接网络做过(当时的测试精度为 97.8%)。虽然本例中的卷积神经网络很简单,但其精度肯定会超过第 2章的密集连接网络。
下列代码将会展示一个简单的卷积神经网络。它是Conv2D层和MaxPooling2D层的堆叠。很快你就会知道这些层的作用。
代码清单 5-1 实例化一个小型的卷积神经网络
from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu'))
重要的是,卷积神经网络接收形状为(image_height, image_width, image_channels)的输入张量(不包括批量维度)。本例中设置卷积神经网络处理大小为(28, 28, 1)的输入张量,这正是 MNIST图像的格式。我们向第一层传入参数input_shape=(28, 28, 1)来完成此设置。
我们来看一下目前卷积神经网络的架构。

可以看到,每个Conv2D层和MaxPooling2D层的输出都是一个形状为(height, width,channels)的 3D张量。宽度和高度两个维度的尺寸通常会随着网络加深而变小。通道数量由传入Conv2D层的第一个参数所控制(32或 64)。
下一步是将最后的输出张量[大小为 (3, 3, 64)]输入到一个密集连接分类器网络中,即Dense层的堆叠,你已经很熟悉了。这些分类器可以处理 1D向量,而当前的输出是 3D张量。
首先,我们需要将 3D输出展平为 1D,然后在上面添加几个Dense层。
代码清单 5-2 在卷积神经网络上添加分类器
model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax'))
我们将进行 10类别分类,最后一层使用带 10个输出的 softmax激活。现在网络的架构如下。
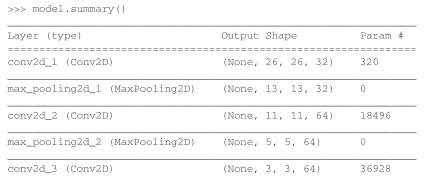

如你所见,在进入两个Dense层之前,形状(3, 3, 64)的输出被展平为形状(576,)的向量。
下面我们在 MNIST数字图像上训练这个卷积神经网络。我们将复用第 2章 MNIST示例中的很多代码。
代码清单 5-3 在 MNIST图像上训练卷积神经网络
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
我们在测试数据上对模型进行评估。
>>> test_loss, test_acc = model.evaluate(test_images, test_labels) >>> test_acc 0.99080000000000001
第 2章密集连接网络的测试精度为 97.8%,但这个简单卷积神经网络的测试精度达到了99.3%,我们将错误率降低了 68%(相对比例)。相当不错!
与密集连接模型相比,为什么这个简单卷积神经网络的效果这么好?要回答这个问题,我们来深入了解Conv2D层和MaxPooling2D层的作用。
5.1.1 卷积运算
密集连接层和卷积层的根本区别在于, Dense层从输入特征空间中学到的是全局模式(比如对于 MNIST数字,全局模式就是涉及所有像素的模式),而卷积层学到的是局部模式(见图 5-1),对于图像来说,学到的就是在输入图像的二维小窗口中发现的模式。在上面的例子中,这些窗口的大小都是 3×3。

图 5-1 图像可以被分解为局部模式,如边缘、纹理等
这个重要特性使卷积神经网络具有以下两个有趣的性质。
- 卷积神经网络学到的模式具有平移不变性(translation invariant)。卷积神经网络在图像右下角学到某个模式之后,它可以在任何地方识别这个模式,比如左上角。对于密集连接网络来说,如果模式出现在新的位置,它只能重新学习这个模式。这使得卷积神经网络在处理图像时可以高效利用数据(因为视觉世界从根本上具有平移不变性),它只需要更少的训练样本就可以学到具有泛化能力的数据表示。
- 卷积神经网络可以学到模式的空间层次结构(spatial hierarchies of patterns),见图 5-2。第一个卷积层将学习较小的局部模式(比如边缘),第二个卷积层将学习由第一层特征组成的更大的模式,以此类推。这使得卷积神经网络可以有效地学习越来越复杂、越来越抽象的视觉概念(因为视觉世界从根本上具有空间层次结构)。
对于包含两个空间轴(高度和宽度)和一个深度轴(也叫通道轴)的 3D张量,其卷积也叫特征图(feature map)。对于 RGB图像,深度轴的维度大小等于 3,因为图像有 3个颜色通道:红色、绿色和蓝色。对于黑白图像(比如 MNIST数字图像),深度等于 1(表示灰度等级)。卷积运算从输入特征图中提取图块,并对所有这些图块应用相同的变换,生成输出特征图(output feature map)。该输出特征图仍是一个 3D张量,具有宽度和高度,其深度可以任意取值,因为输出深度是层的参数,深度轴的不同通道不再像 RGB输入那样代表特定颜色,而是代表过滤器(filter)。过滤器对输入数据的某一方面进行编码,比如,单个过滤器可以从更高层次编码这样一个概念:“输入中包含一张脸。”
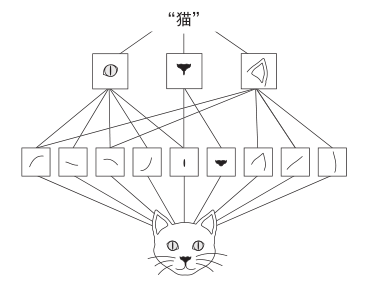
图 5-2 视觉世界形成了视觉模块的空间层次结构:超局部的边缘组合成局部的对象,比如眼睛或耳朵,这些局部对象又组合成高级概念,比如“猫”
在 MNIST示例中,第一个卷积层接收一个大小为(28, 28, 1)的特征图,并输出一个大小为(26, 26, 32)的特征图,即它在输入上计算 32个过滤器。对于这 32个输出通道,每个通道都包含一个 26×26的数值网格,它是过滤器对输入的响应图(response map),表示这个过滤器模式在输入中不同位置的响应(见图 5-3)。这也是特征图这一术语的含义:深度轴的每个维度都是一个特征(或过滤器),而 2D张量output[:, :, n]是这个过滤器在输入上的响应的二维空间图(map)。
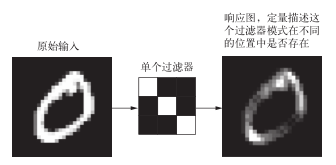
图 5-3 响应图的概念:某个模式在输入中的不同位置是否存在的二维图
卷积由以下两个关键参数所定义。
- 从输入中提取的图块尺寸:这些图块的大小通常是 3×3或 5×5。本例中为 3×3,这是很常见的选择。
- 输出特征图的深度:卷积所计算的过滤器的数量。本例第一层的深度为 32,最后一层的深度是 64。
对于 Keras的Conv2D层,这些参数都是向层传入的前几个参数:Conv2D(output_depth,(window_height, window_width))。
卷积的工作原理:在 3D输入特征图上滑动(slide)这些 3×3或 5×5的窗口,在每个可能的位置停止并提取周围特征的 3D图块[形状为(window_height, window_width, input_depth)]。然后每个 3D图块与学到的同一个权重矩阵[叫作卷积核(convolution kernel)]做张量积,转换成形状为 (output_depth,)的 1D向量。然后对所有这些向量进行空间重组,使其转换为形状为 (height, width, output_depth)的 3D输出特征图。输出特征图中的每个空间位置都对应于输入特征图中的相同位置(比如输出的右下角包含了输入右下角的信息)。举个例子,利用 3×3的窗口,向量output[i, j, :]来自 3D图块input[i-1:i+1,j-1:j+1, :]。整个过程详见图 5-4。
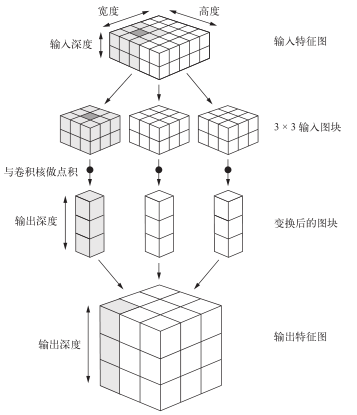
图 5-4 卷积的工作原理
注意,输出的宽度和高度可能与输入的宽度和高度不同。不同的原因可能有两点。
- 边界效应,可以通过对输入特征图进行填充来抵消。
- 使用了步幅(stride),稍后会给出其定义。
我们来深入研究一下这些概念。
1.理解边界效应与填充
假设有一个 5×5的特征图(共 25个方块)。其中只有 9个方块可以作为中心放入一个3×3的窗口,这 9个方块形成一个 3×3的网格(见图 5-5)。因此,输出特征图的尺寸是 3×3。它比输入尺寸小了一点,在本例中沿着每个维度都正好缩小了 2个方块。在前一个例子中你也可以看到这种边界效应的作用:开始的输入尺寸为 28×28,经过第一个卷积层之后尺寸变为26×26。
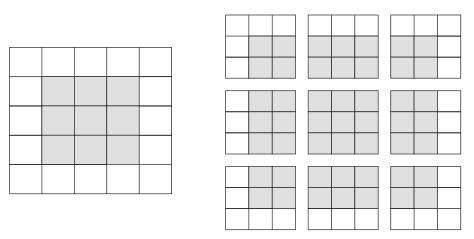
图 5-5 在 5×5的输入特征图中,可以提取 3×3图块的有效位置
如果你希望输出特征图的空间维度与输入相同,那么可以使用填充(padding)。填充是在输入特征图的每一边添加适当数目的行和列,使得每个输入方块都能作为卷积窗口的中心。对于 3×3的窗口,在左右各添加一列,在上下各添加一行。对于 5×5的窗口,各添加两行和两列(见图 5-6)。
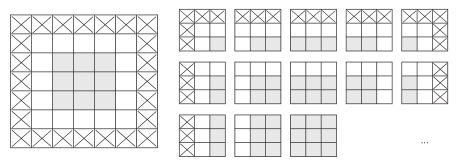
图 5-6 对 5×5的输入进行填充,以便能够提取出 25个 3×3的图块对于Conv2D层,可以通过padding参数来设置填充,这个参数有两个取值:”valid”表示不使用填充(只使用有效的窗口位置);”same”表示“填充后输出的宽度和高度与输入相同”。padding参数的默认值为”valid”。
2.理解卷积步幅
影响输出尺寸的另一个因素是步幅的概念。目前为止,对卷积的描述都假设卷积窗口的中心方块都是相邻的。但两个连续窗口的距离是卷积的一个参数,叫作步幅,默认值为 1。也可以使用步进卷积(strided convolution),即步幅大于 1的卷积。在图 5-7中,你可以看到用步幅为 2的 3×3卷积从 5×5输入中提取的图块(无填充)。
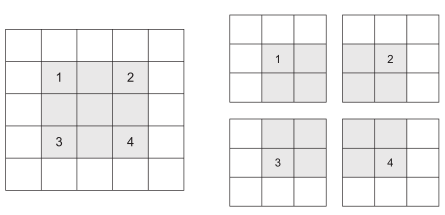
图 5-7 2×2步幅的 3×3卷积图块
步幅为 2意味着特征图的宽度和高度都被做了 2倍下采样(除了边界效应引起的变化)。虽然步进卷积对某些类型的模型可能有用,但在实践中很少使用。熟悉这个概念是有好处的。
为了对特征图进行下采样,我们不用步幅,而是通常使用最大池化(max-pooling)运算,你在第一个卷积神经网络示例中见过此运算。下面我们来深入研究这种运算。
5.1.2 最大池化运算
在卷积神经网络示例中,你可能注意到,在每个 MaxPooling2D层之后,特征图的尺寸都会减半。例如,在第一个MaxPooling2D层之前,特征图的尺寸是 26×26,但最大池化运算将其减半为 13×13。这就是最大池化的作用:对特征图进行下采样,与步进卷积类似。
最大池化是从输入特征图中提取窗口,并输出每个通道的最大值。它的概念与卷积类似,但是最大池化使用硬编码的max张量运算对局部图块进行变换,而不是使用学到的线性变换(卷积核)。最大池化与卷积的最大不同之处在于,最大池化通常使用 2×2的窗口和步幅 2,其目的是将特征图下采样 2倍。与此相对的是,卷积通常使用 3×3窗口和步幅 1。
为什么要用这种方式对特征图下采样?为什么不删除最大池化层,一直保留较大的特征图?我们来这么做试一下。这时模型的卷积基(convolutional base)如下所示。
model_no_max_pool = models.Sequential() model_no_max_pool.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(28, 28, 1))) model_no_max_pool.add(layers.Conv2D(64, (3, 3), activation='relu')) model_no_max_pool.add(layers.Conv2D(64, (3, 3), activation='relu'))
该模型的架构如下。

这种架构有什么问题?有如下两点问题。
- 这种架构不利于学习特征的空间层级结构。第三层的 3×3窗口中只包含初始输入的7×7窗口中所包含的信息。卷积神经网络学到的高级模式相对于初始输入来说仍然很小,这可能不足以学会对数字进行分类(你可以试试仅通过 7像素×7像素的窗口观察图像来识别其中的数字)。我们需要让最后一个卷积层的特征包含输入的整体信息。
- 最后一层的特征图对每个样本共有 22×22×64=30 976个元素。这太多了。如果你将其展平并在上面添加一个大小为 512的Dense层,那一层将会有 1580万个参数。这对于这样一个小模型来说太多了,会导致严重的过拟合。
简而言之,使用下采样的原因,一是减少需要处理的特征图的元素个数,二是通过让连续卷积层的观察窗口越来越大(即窗口覆盖原始输入的比例越来越大),从而引入空间过滤器的层级结构。
注意,最大池化不是实现这种下采样的唯一方法。你已经知道,还可以在前一个卷积层中使用步幅来实现。此外,你还可以使用平均池化来代替最大池化,其方法是将每个局部输入图块变换为取该图块各通道的平均值,而不是最大值。但最大池化的效果往往比这些替代方法更好。简而言之,原因在于特征中往往编码了某种模式或概念在特征图的不同位置是否存在(因此得名特征图),而观察不同特征的最大值而不是平均值能够给出更多的信息。因此,最合理的子采样策略是首先生成密集的特征图(通过无步进的卷积),然后观察特征每个小图块上的最大激活,而不是查看输入的稀疏窗口(通过步进卷积)或对输入图块取平均,因为后两种方法可能导致错过或淡化特征是否存在的信息。
现在你应该已经理解了卷积神经网络的基本概念,即特征图、卷积和最大池化,并且也知道如何构建一个小型卷积神经网络来解决简单问题,比如 MNIST数字分类。下面我们将介绍更加实用的应用。