《Python 核心编程》
第 4 章 多线程编程
> 在Python 中,你可以启动一个线程,但却无法停止它。
> 对不起,你必须要等到它执行结束。
所以,就像[comp.lang.python]一样,然后呢?
—Cliff Wells, Steve Holden
(和 Timothy Delaney),2002 年 2 月
本章内容:
- 简介/动机;
- 线程和进程;
- 线程和 Python;
- thread 模块;
- threading 模块;
- 单线程和多线程执行对比;
- 多线程实践;
- 生产者-消费者问题和 Queue/queue 模块;
- 线程的替代方案;
- 相关模块。
本章将研究几种使代码更具并行性的方法。开始的几节会讨论进程和线程的区别。然后介绍多线程编程的概念,并给出一些 Python 多线程编程的功能(已经熟悉多线程编程的读者可以直接跳到 4.3.5 节)。本章最后几节将给出几个使用 threading 模块和 Queue 模块实现Python 多线程编程的例子。
- 4.1简介/动机
在多线程(multithreaded,MT)编程出现之前,计算机程序的执行是由单个步骤序列组成的,该序列在主机的 CPU 中按照同步顺序执行。无论是任务本身需要按照步骤顺序执行, 还是整个程序实际上包含多个子任务,都需要按照这种顺序方式执行。那么,假如这些子任务相互独立,没有因果关系(也就是说,各个子任务的结果并不影响其他子任务的结果),这种做法是不是不符合逻辑呢?要是让这些独立的任务同时运行,会怎么样呢?很明显,这种并行处理方式可以显著地提高整个任务的性能。这就是多线程编程。
多线程编程对于具有如下特点的编程任务而言是非常理想的:本质上是异步的;需要多个并发活动;每个活动的处理顺序可能是不确定的,或者说是随机的、不可预测的。这种编程任务可以被组织或划分成多个执行流,其中每个执行流都有一个指定要完成的任务。根据应用的不同,这些子任务可能需要计算出中间结果,然后合并为最终的输出结果。
计算密集型的任务可以比较容易地划分成多个子任务,然后按顺序执行或按照多线程方式执行。而那种使用单线程处理多个外部输入源的任务就不那么简单了。如果不使用多线程,要实现这种编程任务就需要为串行程序使用一个或多个计时器,并实现一个多路复用方案。
一个串行程序需要从每个 I/O 终端通道来检查用户的输入;然而,有一点非常重要,程序在读取 I/O 终端通道时不能阻塞,因为用户输入的到达时间是不确定的,并且阻塞会妨碍其他 I/O 通道的处理。串行程序必须使用非阻塞 I/O 或拥有计时器的阻塞 I/O(以保证阻塞只是暂时的)。
由于串行程序只有唯一的执行线程,因此它必须兼顾需要执行的多个任务,确保其中的某个任务不会占用过多时间,并对用户的响应时间进行合理的分配。这种任务类型的串行程序的使用,往往造成非常复杂的控制流,难以理解和维护。
使用多线程编程,以及类似 Queue 的共享数据结构(本章后面会讨论的一种多线程队列数据结构),这个编程任务可以规划成几个执行特定函数的线程。
- UserRequestThread:负责读取客户端输入,该输入可能来自 I/O 通道。程序将创建多个线程,每个客户端一个,客户端的请求将会被放入队列中。
- RequestProcessor:该线程负责从队列中获取请求并进行处理,为第 3 个线程提供输出。
- ReplyThread:负责向用户输出,将结果传回给用户(如果是网络应用),或者把数据写到本地文件系统或数据库中。
使用多线程来规划这种编程任务可以降低程序的复杂性,使其实现更加清晰、高效、简洁。每个线程中的逻辑都不复杂, 因为它只有一个要完成的特定作业。比如,
UserRequestThread 的功能仅仅是读取用户输入,然后把输入数据放到队列里,以供其他线程后续处理。每个线程都有其明确的作业,你只需要设计每类线程去做一件事,并把这件事情做好就可以了。这种特定任务线程的使用与亨利·福特生产汽车的流水线模型有些许相似。
4.2 线程和进程
4.2.1 进程
计算机程序只是存储在磁盘上的可执行二进制(或其他类型)文件。只有把它们加载到内存中并被操作系统调用,才拥有其生命期。进程(有时称为重量级进程)则是一个执行中的程序。每个进程都拥有自己的地址空间、内存、数据栈以及其他用于跟踪执行的辅助数据。操作系统管理其上所有进程的执行,并为这些进程合理地分配时间。进程也可以通过派生(fork 或 spawn)新的进程来执行其他任务,不过因为每个新进程也都拥有自己的内存和数据栈等,所以只能采用进程间通信(IPC)的方式共享信息。
4.2.2 线程
线程(有时候称为轻量级进程)与进程类似,不过它们是在同一个进程下执行的,并共享相同的上下文。可以将它们认为是在一个主进程或“主线程”中并行运行的一些“迷你进程”。
线程包括开始、执行顺序和结束三部分。它有一个指令指针,用于记录当前运行的上下文。当其他线程运行时,它可以被抢占(中断)和临时挂起(也称为睡眠)——这种做法叫做让步(yielding)。
一个进程中的各个线程与主线程共享同一片数据空间,因此相比于独立的进程而言,线程间的信息共享和通信更加容易。线程一般是以并发方式执行的,正是由于这种并行和数据共享机制,使得多任务间的协作成为可能。当然,在单核 CPU 系统中,因为真正的并发是不可能的,所以线程的执行实际上是这样规划的:每个线程运行一小会儿,然后让步给其他线程(再次排队等待更多的 CPU 时间)。在整个进程的执行过程中,每个线程执行它自己特定的任务,在必要时和其他线程进行结果通信。
当然,这种共享并不是没有风险的。如果两个或多个线程访问同一片数据,由于数据访问顺序不同,可能导致结果不一致。这种情况通常称为竞态条件(race condition)。幸运的是,大多数线程库都有一些同步原语,以允许线程管理器控制执行和访问。
另一个需要注意的问题是,线程无法给予公平的执行时间。这是因为一些函数会在完成前保持阻塞状态,如果没有专门为多线程情况进行修改,会导致 CPU 的时间分配向这些贪婪的函数倾斜。
4.3 线程和 Python
本节将讨论在如何在 Python 中使用线程,其中包括全局解释器锁对线程的限制和一个快速的演示脚本。
4.3.1 全局解释器锁
Python 代码的执行是由 Python 虚拟机(又名解释器主循环)进行控制的。Python 在设计时是这样考虑的,在主循环中同时只能有一个控制线程在执行,就像单核 CPU 系统中的多进程一样。内存中可以有许多程序,但是在任意给定时刻只能有一个程序在运行。同理,尽管 Python 解释器中可以运行多个线程,但是在任意给定时刻只有一个线程会被解释器执行。
对 Python 虚拟机的访问是由全局解释器锁(GIL)控制的。这个锁就是用来保证同时只能有一个线程运行的。在多线程环境中,Python 虚拟机将按照下面所述的方式执行。
1.设置 GIL。
2.切换进一个线程去运行。
3.执行下面操作之一。
- a.指定数量的字节码指令。
- b.线程主动让出控制权(可以调用 time.sleep(0)来完成)。
4.把线程设置回睡眠状态(切换出线程)。
5.解锁 GIL。
6.重复上述步骤。
当调用外部代码(即,任意 C/C++扩展的内置函数)时,GIL 会保持锁定,直至函数执行结束(因为在这期间没有 Python 字节码计数)。编写扩展函数的程序员有能力解锁 GIL, 然而,作为 Python 开发者,你并不需要担心 Python 代码会在这些情况下被锁住。
例如,对于任意面向 I/O 的 Python 例程(调用了内置的操作系统 C 代码的那种),GIL 会在 I/O 调用前被释放,以允许其他线程在 I/O 执行的时候运行。而对于那些没有太多 I/O 操作的代码而言,更倾向于在该线程整个时间片内始终占有处理器(和 GIL)。换句话说就是,I/O 密集型的 Python 程序要比计算密集型的代码能够更好地利用多线程环境。
如果你对源代码、解释器主循环和GIL 感兴趣,可以看看Python/ceval.c 文件。
4.3.2 退出线程
当一个线程完成函数的执行时,它就会退出。另外,还可以通过调用诸如 thread.exit()之类的退出函数,或者 sys.exit()之类的退出 Python 进程的标准方法,亦或者抛出 SystemExit 异常,来使线程退出。不过,你不能直接“终止”一个线程。
下一节将会详细讨论两个与线程相关的Python 模块,不过在这两个模块中,不建议使用thread 模块。给出这个建议有很多原因,其中最明显的一个原因是在主线程退出之后,所有其他线程都会在没有清理的情况下直接退出。而另一个模块 threading 会确保在所有“重要的” 子线程退出前,保持整个进程的存活(对于“重要的”这个含义的说明,请阅读下面的核心提示:“避免使用 thread 模块”)。
而主线程应该做一个好的管理者,负责了解每个单独的线程需要执行什么,每个派生的线程需要哪些数据或参数,这些线程执行完成后会提供什么结果。这样,主线程就可以收集每个线程的结果,然后汇总成一个有意义的最终结果。
4.3.3 在 Python 中使用线程
Python 虽然支持多线程编程,但是还需要取决于它所运行的操作系统。如下操作系统是支持多线程的:绝大多数类 UNIX 平台(如 Linux、Solaris、Mac OS X、*BSD 等),以及Windows 平台。Python 使用兼容POSIX 的线程,也就是众所周知的 pthread。
默认情况下,从源码构建的 Python(2.0 及以上版本)或者 Win32 二进制安装的 Python, 线程支持是已经启用的。要确定你的解释器是否支持线程,只需要从交互式解释器中尝试导入 thread 模块即可,如下所示(如果线程是可用的,则不会产生错误)。
>>> import thread >>>
如果你的Python 解释器没有将线程支持编译进去,模块导入将会失败。
>>> import thread
Traceback (innermost last):
File "<stdin>", line 1, in ?
ImportError: No module named thread
这种情况下,你可能需要重新编译你的 Python 解释器才能够使用线程。一般可以在调用configure 脚本的时候使用–with-thread 选项。查阅你所使用的发行版本的 README 文件,来获取如何在你的系统中编译线程支持的Python 的指定指令。
4.3.4 不使用线程的情况
在第一个例子中,我们将使用 time.sleep()函数来演示线程是如何工作的。time.sleep()函数需要一个浮点型的参数,然后以这个给定的秒数进行“睡眠”,也就是说,程序的执行会暂时停止指定的时间。
创建两个时间循环:一个睡眠 4 秒(loop0());另一个睡眠 2 秒(loop1())(这里使用“loop0”和“loop1”作为函数名,暗示我们最终会有一个循环序列)。如果在一个单进程或单线程的 程序中顺序执行 loop0()和loop1(),就会像示例 4-1 中的 onethr.py 一样,整个执行时间至少会达到 6 秒钟。而在启动 loop0()和 loop1()以及执行其他代码时,也有可能存在 1 秒的开销,使得整个时间达到 7 秒。
示例 4-1 使用单线程执行循环(onethr.py)
该脚本在一个单线程程序里连续执行两个循环。一个循环必须在另一个开始前完成。总共消耗的时间是每个循环所用时间之和。
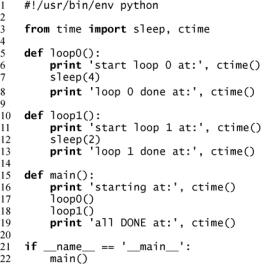
可以通过执行 onethr.py 来验证这一点,下面是输出结果。
$ onethr.py starting at: Sun Aug 13 05:03:34 2006 start loop 0 at: Sun Aug 13 05:03:34 2006 loop 0 done at: Sun Aug 13 05:03:38 2006 start loop 1 at: Sun Aug 13 05:03:38 2006 loop 1 done at: Sun Aug 13 05:03:40 2006 all DONE at: Sun Aug 13 05:03:40 2006
现在,假设 loop0()和 loop1()中的操作不是睡眠,而是执行独立计算操作的函数,所有结果汇总成一个最终结果。那么,让它们并行执行来减少总的执行时间是不是有用的呢?这就是现在要介绍的多线程编程的前提。
4.3.5 Python 的 threading 模块
Python 提供了多个模块来支持多线程编程,包括 thread、threading 和 Queue 模块等。程序是可以使用 thread 和 threading 模块来创建与管理线程。thread 模块提供了基本的线程和锁定支持;而 threading 模块提供了更高级别、功能更全面的线程管理。使用 Queue 模块,用户可以创建一个队列数据结构,用于在多线程之间进行共享。我们将分别来查看这几个模块, 并给出几个例子和中等规模的应用。
| 核心提示:避免使用 thread 模块 |
| 推荐使用更高级别的 threading 模块,而不使用 thread 模块有很多原因。threading 模块更加先进,有更好的线程支持,并且 thread 模块中的一些属性会和 threading 模块有冲突。另一个原因是低级别的 thread 模块拥有的同步原语很少(实际上只有一个),而 threading模块则有很多。不过,出于对 Python 和线程学习的兴趣,我们将给出使用 thread 模块的一些代码。给出这些代码只是出于学习目的,希望它能够让你更好地领悟为什么应该避免使用thread 模块。我们还将展示如何使用更加合适的工具,如 threading 和 Queue 模块中的那些方法。避免使用 thread 模块的另一个原因是它对于进程何时退出没有控制。当主线程结束时,所有其他线程也都强制结束,不会发出警告或者进行适当的清理。如前所述,至少threading 模块能确保重要的子线程在进程退出前结束。我们只建议那些想访问线程的更底层级别的专家使用thread 模块。为了强调这一点, 在Python3 中该模块被重命名为_thread。你创建的任何多线程应用都应该使用 threading 模块或其他更高级别的模块。 |